
我们非常激动地发布了 Qwen-Image,这是 Qwen 系列中的一个图像生成基础模型,在 复杂文本渲染 和 精确图像编辑 方面取得了显著进展。实验显示,该模型在图像生成和编辑方面具有强大的通用能力,特别是在文本渲染方面表现出色,尤其是在中文上。
Qwen-Image 是阿里通义千问团队开源的 20B 参数MMDiT模型,是通义千问系列中首个图像生成基础模型,模型在复杂文本渲染和精确图像编辑方面表现出色,支持多行布局、段落级文本生成及细粒度细节呈现,中英文都能实现高保真输出。Qwen-Image 在通用图像生成和编辑任务中展现出强大的能力,支持多种艺术风格和高级编辑操作。
主要特性包括
卓越的文本渲染能力: Qwen-Image 在复杂文本渲染方面表现出色,支持多行布局、段落级文本生成以及细粒度细节呈现。无论是英语还是中文,均能实现高保真输出。
一致性的图像编辑能力: 通过增强的多任务训练范式,Qwen-Image 在编辑过程中能出色地保持编辑的一致性。
强大的跨基准性能表现: 在多个公开基准测试中的评估表明,Qwen-Image 在各类生成与编辑任务中均获得SOTA,是一个强大的图像生成基础模型。
项目地址:https://github.com/QwenLM/Qwen-Image

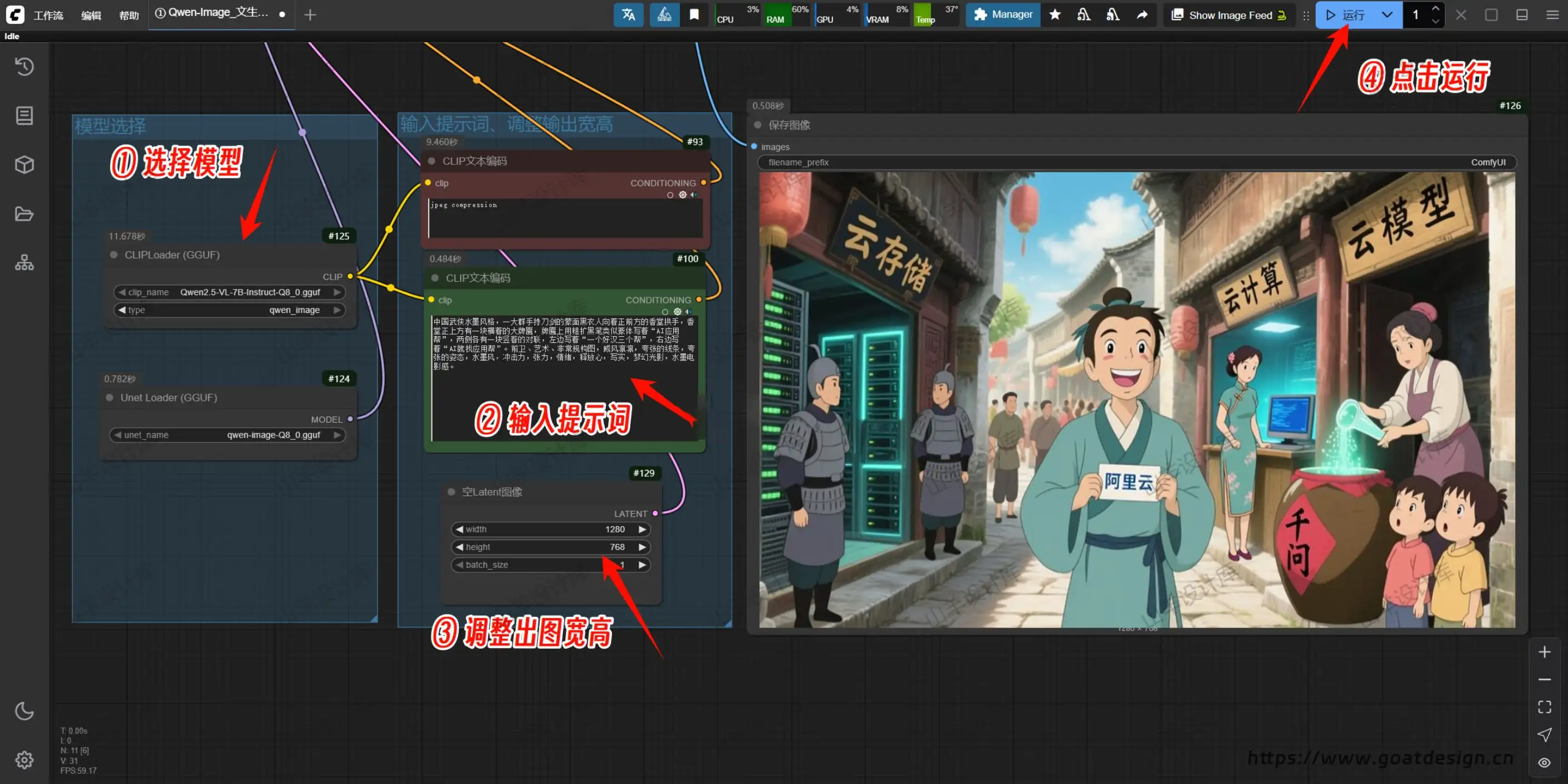
配置要求:
操作系统:Windows 10/11 64位
内存:32G以上
显卡:不同模型对显存要求不一样,至少8G及以上显存的英伟达(NVIDIA)显卡
CUDA:显卡驱动更新到最新后,支持的CUDA版本大于等于12.8版本
启动包解压完约15G,模型共84G,可以只选择需要的模型,要留足硬盘空间
案例展示
它的一个突出能力是在各种图像中实现高保真度的文本渲染。无论是像英文这样的字母语言还是像中文这样的表意文字,Qwen-Image 都能以惊人的准确性保留排版细节、布局连贯性和上下文和谐。文本不仅仅是叠加在图像上,而是无缝地融入视觉结构中。

除了文本之外,Qwen-Image 还擅长支持多种艺术风格的一般图像生成。从逼真的场景到印象派画作,从动漫美学到极简设计,该模型能够灵活适应创意提示,使其成为艺术家、设计师和故事讲述者的多功能工具。

当谈到图像编辑时,Qwen-Image 远远超出了简单的调整。它能够实现诸如风格转换、对象插入或移除、细节增强、图像中的文本编辑,甚至人体姿态操控等高级操作——所有这些都通过直观的输入和连贯的输出来完成。这种级别的控制使专业级编辑变得触手可及,即使是日常用户也能轻松上手。
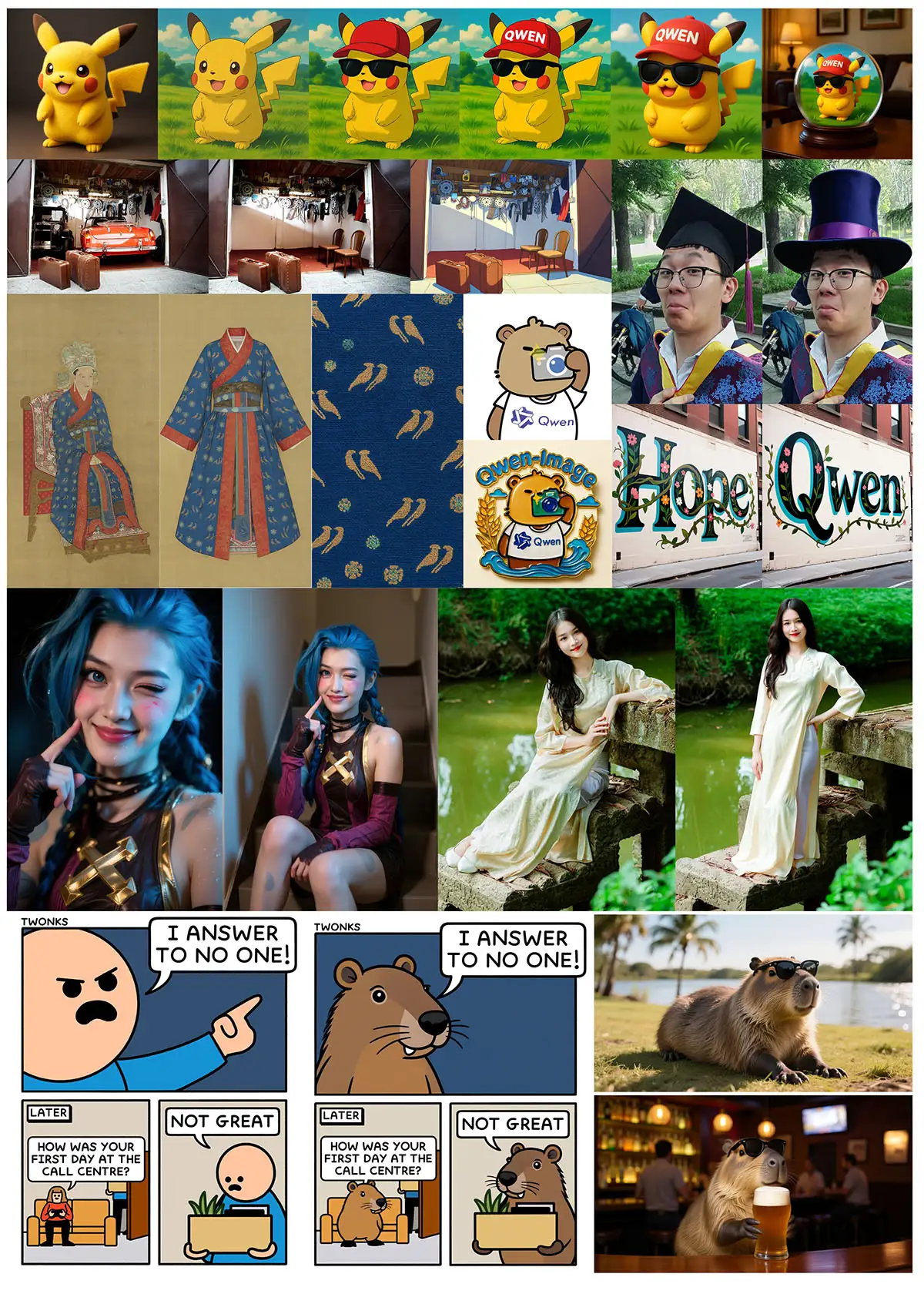
但 Qwen-Image 不仅能创建或编辑——它还能理解。它支持一系列图像理解任务,包括物体检测、语义分割、深度和边缘(Canny)估计、新视图合成以及超分辨率。尽管从技术上看这些能力各不相同,但都可以被视为由深度视觉理解驱动的智能图像编辑的专业形式。

综合来看,这些特性使得 Qwen-Image 不仅仅是一个生成漂亮图片的工具,而是一个集成了智能视觉创作与操控的基础模型——在这里,语言、布局与图像汇聚一堂。
本站信息来自网络和用户自行分享,版权争议与本站无关。您必须在下载后的24个小时之内,从您的电脑中彻底删除上述内容。如果您喜欢该程序,请支持正版,得到更好的正版服务。如有侵权请邮件与我们联系处理。


